


![[Quiz] Part II: The Search Technique You Should be Using (But Probably Aren't) Icon - Relativity Blog](/sites/relativity/cache/file/3573264C-801A-4EAA-8AB7F3D1B8E1C2C2.png)
Back in December, we explained how Regular Expressions (RegEx) works and some basic ways it can be used in dtSearch and structured analytics. To jog your memory, RegEx is a form of advanced searching that looks for specific patterns instead of certain terms and phrases. It has the ability to hit results that no other type of searching can, offering e-discovery practitioners big improvements to their typical workflows.
We’ve heard a few stories from the field lately of customers who have successfully employed RegEx. I recently got into a passionate discussion with iDS Senior Manager Louis Martin. Here’s what he had to say:
“RegEx is a fantastic tool, and we use it all the time to easily search for challenging or very specific terms. Consider the dash symbol—a commonly requested, yet difficult-to-manage search term. We can find it with RegEx.
Another big way we use RegEx is to aid in removing sections of text that might cause documents to be misidentified. For example, we can clean up email footers and remove text that might erroneously add conceptual content to our analytics index, such as a large legal disclaimer.”
With RegEx evangelists like Louis out there, we thought we were due for a follow-up post. Here are a couple more ways to strengthen your workflows with RegEx.
Sneaking One Past dtSearch
One of the most common myths we hear is that reviewers can’t search for certain symbols that may be relevant to a case. However, this is far from the truth. Here’s a fun example.
Imagine you’re working on a chemical patent case, and you need to identify files that refer to certain chemicals and compound ratios associated with them. You’ve received a court order that requires you to produce all documents containing the term "35%" and you’d like to create a search string to locate them.
In dtSearch, the % symbol is reserved as the fuzzy searching character—where % indicates how many characters in the search term will be ignored—and would thus return completely different results than the ones you’re looking for.
Luckily, we can use “metacharacters,” the RegEx building blocks, to construct a regular expression that returns our desired results.
You may recall from our previous post that the metacharacter \d represents a whole number 0 to 9. Similarly, \W (note the capitalization) represents any symbol, such as # or, you guessed it, % (while \w represents any alphanumeric character—a to z or 0 to 9).
This metacharacter is a convenient way to locate percentages that appear within your files. To search for the term “35%,” you first need to make the % sign a searchable character in your dtSearch index. Next, your string in dtSearch would look like this: "##35\W." Or, if you’re looking for any string of two or three numbers followed by a % sign, you can use a RegEx such as "##\d{2,3}\W" or "##[0-9]{2,3}\W."
Note that this string would return multiple other terms as well, such as “35#” or “35!” if you chose to make # or ! symbols searchable. You can choose which symbols you’d like the system to look for, making RegEx even more practical.
RegEx in Conceptual Analytics
Index building is an essential component of conceptual analytics, and you need “clean” indexes to ensure you’re getting the best results. For example, when building an index, it’s a best practice to strip out the email header fields (i.e., To, From, CC, and subject line) to ensure your results are only based on the important information found in the body of an email.
If you’re involved in a non-English or multi-language matter, you can use RegEx to strip out non-English header information to prevent it from affecting your analytics index.
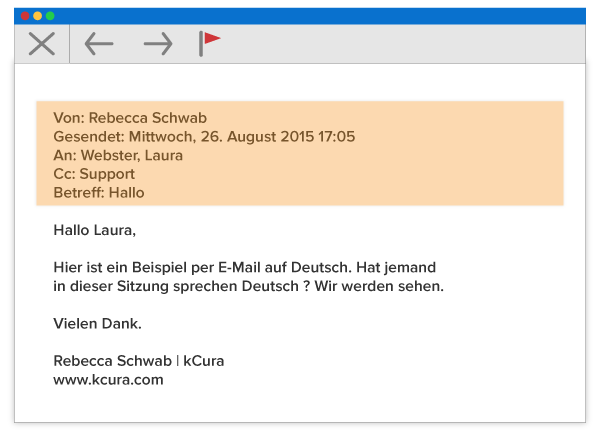
Knowing analytics turns text into one long string, with line breaks represented by the characters \r\n, we can employ a single RegEx to match for the German headers to be stripped out in the example above:
(?i)(von:.*?betreff:.*?(\r\n))
Have we lost you? Okay, it does take some practice and maybe a little help from a resident RegEx expert. But the possibilities are there, and there are plenty of resources, like RegEx documentation and webinars, to help you along the way.
Put Your Skills to the Test
Ready to take your RegEx knowledge for a spin? Try solving a few quick puzzles on your own with this three-question quiz.

![[Quiz] Part II: The Search Technique You Should be Using (But Probably Aren't) Icon - Relativity Blog](/sites/relativity/cache/file/9D6C881E-EA56-4274-908F23C69E451C6A_bloglandinglogo.png)
![[Quiz] Part II: The Search Technique You Should be Using (But Probably Aren't) Icon - Relativity Blog](/sites/relativity/cache/file/3FD87E7B-45C3-4BBD-8C64CB3665810F8C_bloglandinglogo.png)




